Cats2D Multiphysics > Research Topics > The dismal state of scientific computing
All unpublished results shown here are Copyright © 2015–2019 Andrew Yeckel, all rights reserved
The dismal state of scientific computing
I share here some essays I've written about the poor state of education and practice in scientific computing, and the flaws inherent to traditional publishing as a primary means of disseminating our research.
Eating the seed corn
I have seen very little advancement in the quality and impact of physics-based computing over the past twenty years. Computing hardware has improved dramatically and people are solving larger, more complicated problems than ever before, but the lack of genuine intellectual advancement is appalling. So many things have gone wrong I hardly know where to begin.
Commercial software for structural and continuum mechanics has advanced significantly, but remains quite expensive. Single user, single processor licenses cost tens of thousands of dollars annually, and the extra charges for multiple users and multiple processors are steep. This kind of software remains difficult to use, and setting up problems is often labor intensive. CAD, mesh generation, and post-processing often are handled by separate applications. Workflow becomes a significant issue when moving data through a chain of applications to carry out these steps.
Personally I think the commercial products are too much of a Frankenstein. Nobody has been able to streamline this kind of analysis into an intuitive, low effort workflow that can be trusted to produce reliable results. It is possible, with some effort, to carry out impressive and useful simulations with these products. It is also easily possible to generate solutions of low reliability and low utility, and that is what often happens.
Let me be clear: I am not criticizing the people who create and sell these products. It took smart people many years of hard work to build this industry. They've identified a market and found a way to serve it. But, like so many other things, these products are creatures of their environment, which in this case is burdened by a poorly trained user base. Every company in this industry expends considerable effort training their customers, making user support a large part of the high cost of these products. But it isn't enough.
Effective use of these products requires bona fide skills. Fluid mechanics is hard. It requires formal study. It takes time to absorb. Often it is nonintuitive, and subtleties abound. Throw in convective heat and mass transfer and things start to get really complicated. Everything is coupled and nonlinear. The notion that code => visualization => understanding is a straightforward path is deeply misguided.
I have reviewed many papers, primarily written by academic researchers, in which commercial products have been used badly. Problems are formulated incorrectly, physical models are chosen inappropriately, algorithms are used with bad parameter settings, and so on. And always lurking in the background are space and time discretization error, which often are far worse than casual users of these products imagine.
Two things stand out to me from all the papers I've reviewed. Call them red flags. One of these is a failure to properly use the divergence and gradient operators when writing conservation equations. Example: writing the continuity equation as grad(u) instead of div(u). Seriously. I've seen this many times and as soon as I see it I know the rest of the paper is going to be full of mistakes. The other is a near complete absence of boundary conditions. Whenever I see this I proceed from the assumption that if they don't write them down, they don't know how.
In my view people who don't know the difference between grad(u) and div(u) are unlikely to carry out or understand the basic checks to which any CFD solution should be subjected. Does it satisfy the putative boundary conditions? Does it conserve mass locally and globally? Does it violate any other obvious physical constraints? Do the time scales seem right? Novice users often fail to notice defects of this nature in the solutions they compute, even when I spot them easily in the figures they've presented.
Nothing is more telling than the abysmal presentation of data generated by these codes. The ugly and useless plots I've seen indicate there is plenty of blame to go around. Velocity vectors show nothing. They're terrible. Yet judging from the frequency of their use in papers I've reviewed and conference talks I've attended, they are the de facto standard in CFD. Why? They're easy. High quality streamlines or path lines are far more informative, but they are much harder to execute well, so they are used far less often.
A more serious, better trained user base would demand better visualization, better solution analysis, and better solution diagnostics than are generally offered. Everyone concerned would benefit. This goes along with the allied need for better trained workers to develop the physics-based simulation tools of the future. Unfortunately these things are unlikely to come about without a sea change in how scientific computing is taught and incorporated into research within our universities.
The basic problem is that faculty principal investigators have neither the time, nor the inclination, to actively engage in software application development. Those who try are usually driven out or marginalized. These aspects are delegated to trainees who are expected to educate themselves in code development. In this research paradigm, the state of knowledge of the principal investigator decays while the state of computing marches forward. The result is that senior faculty who were anointed experts long ago based on a few years of serious computing are no longer experts at all. As a consequence the intellectual scaffolding for this kind of work is worse now than it was twenty years ago, though it should be much better.
Much of computing can be self-taught, or learned with modest instruction. In contrast, working at the forefront of physics-based computing requires years of experience, a sound mentorship, and ongoing professional development. Staying close to the software is essential. These skills aren't like riding a bike. Stop using them and your entire intellectual portfolio in computing will atrophy within a few years.
Armchair generals.... I realize what I'm saying here is harsh. But let me come at it a different way. Consider Taylor or Batchelor, for example. They used classical methods in mathematics to solve many interesting problems in fluid mechanics. Did they ever subsequently lose their ability to solve any of these problems after they had solved them once? Did Van Dyke forget how to apply perturbation methods, or did Acrivos forget how to match asymptotic expansions? I bet not. But it is perfectly normal that a faculty principle investigator is unable to reproduce computational solutions obtained by a trainee because of a lack of relevant computing skills. When that trainee departs, or soon after, the PI loses the ability to reproduce those solutions, at least not without great effort.
I submit that this situation is pathological. If someone purports to be a computational physics expert of some sort, that person ought to maintain the ability to reproduce previous analyses as well as conduct new, novel analyses. In my view of professional development, the acquisition of such abilities should be cumulative and progressive, not sporadic and ephemeral. Physics-based computing is still a new area, full of surprises and unforeseen challenges, carried out on a constantly evolving playfield of hardware advances. Mastery is never achieved, it is only pursued. Stopping the chase guarantees a rapid decline in ability to lead.
Vetrate di Chiesa
Metis partitioning of a mesh for nested dissection of the Jacobian matrix in Cats2D:
Preaching from the pulpit again, here are my thoughts on how to rank the following activities in terms of their importance to CFD:
Numerical methods > Algorithms > Serial optimization > Parallelization
Consider Gaussian elimination. Factorizing a dense matrix requires O(N3) operations. Tricks can be applied here and there to reduce the multiplier, but there are no obvious ways to reduce the exponent (there are some unobvious ways, but these are complicated and not necessarily useful). This scaling is brutal at large problem sizes. But we need Gaussian elimination, which affects everything else downstream.
To deal with this we build bigger, faster computers. When I started it was vector supercomputers. Later came parallel supercomputers. Now we have machines built from GPUs. Using any or all of these approaches to mitigate the pain of the N3 scaling of Gaussian elimination is futile. Increasing N by a factor of ten means increasing the operations by 1000. So parallelizing our problem across 1000 processors gains us a factor of ten in problem size if the parallelization is ideal, and a factor of five at best under actual conditions. It isn't much return for the effort.
Of course no one working in CFD factorizes a dense Jacobian. Sparse matrix methods are used instead. A simple band solver reduces the operation scaling to O(N), for example. A multifrontal solver does not scale so simply, but scales much better than O(N2) on the problems solved by Cats2D. Popular Jacobian-free alternatives also generally scale better than O(N2). By choosing an algorithm that takes advantage of special characteristics of the problem it is possible to reduce operations by a factor of N or more, where N is typically greater than 105 and often much larger than that. Reducing the exponent on N is where the big gains are to be found and this can only done at the algorithm level.
This is a simple example, but I have encountered this theme many times. The first working version of an algorithm often can be sped up by a factor of ten, and sometimes much, much more. I once rewrote someone else's "parallel" code as a serial code. When I was done my serial version was 10,000 times faster than the parallel version. There is no way hardware improvements can compensate for a poorly chosen or badly implemented algorithm. Far too often I've heard parallel computing offered as the solution to what ails CFD. It's totally misguided.
Now let's look more closely at the progressive improvements Goodwin made to his solver these past few years. His starting point, what he calls "Basic Frontal Solver" in the graph, was written in 1992. Before discussing the performance gains in this graph, I want to emphasize that this "basic" solver is not slow. It has many useful optimizations. In this early form it was already faster than some widely used frontal solvers of its day, including the one we were using in Scriven's group.

Still back in 1992 Goodwin added two major improvements, static condensation ("SC") and simultaneous elimination of equations ("Four Pivots") by multirank outer products using BLAS functions. These changes tripled the speed of the solver, making it much faster than its competitors of the day. Note that these improvements are entirely algorithmic and serial in nature, without multithreading or other parallelism. For the next 25 years we sailed along with this powerful tool, which, remarkably, remains competitive with modern versions of UMFPACK and SuperLU.
At the end of 2014 Goodwin climbed back aboard and increased solver speed by a factor of six using nested dissection to carry out the assembly and elimination of the equations. Again this was done by improving the algorithm, rather than by parallelizing it. Using multithreading with BLAS functions to eliminate many equations simultaneously contributed another factor of three, a worthy gain, but small in comparison to the cumulative speedup of the solver by serial algorithmic improvements, which is a factor of twenty compared to the basic solver.
I've simplified things a bit because these speedups are specific to the problem used to benchmark the code. In particular they fail to consider the scaling of factorization time with problem size. This next plot shows that Goodwin has changed the scaling approximately from O(N1.5) to O(N1.2), primarily attributable to nested dissection. The payoff grows with problem size, the benefit of which can hardly be overstated. Not to be overlooked, he also reduced the memory requirement by a factor of ten, allowing much larger problems to fit into memory.
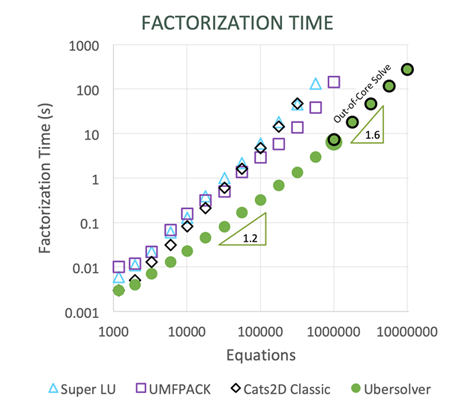
One million unknowns in less than ten seconds on a rather pathetic 2013 MacBook Air (two cores, 1.3 GHz, 4 Gb memory). This is just good programming. Big shots at supercomputer centers think they've hit the ball out of the park if they can get a factor of sixty speedup by parallelizing their code and running it on 256 processors. It's the Dunning-Kruger effect on steroids.
Parallelizing a poorly optimized algorithm is a waste of time. Optimizing a badly conceived algorithm is a waste of time. Applying a well conceived algorithm to an inappropriate numerical method is a waste of time. Failure to understand these things has led to a colossal waste of computing and human resources.
Bridge over troubled water
I have a low aptitude for foreign languages. I worked in restaurant kitchens staffed with Spanish speakers where I learned the names of ingredients and dishes, and a few words of a saltier nature. I lived a short time in Germany, where I managed to learn what I call restaurant menu and street sign German. What these situations had in a common was a narrow vocabulary of a specific nature, used without grammar or composition to speak of.
In regard to spoken language, we use terms such as fluent, proficient, and conversational to rate skill. There is no precise meaning to these ratings, but they are usefully descriptive because we all know from personal experience in our native language what it means to be fluent. Someone who is merely proficient at a foreign language may well overestimate their ability and call themself fluent, but no serious job seeker would try to pass off my rudimentary skills in Spanish or German as fluency or even proficiency. It isn't credible.
The situation with computer languages, unfortunately, seems totally unrestrained by comparison. Everyone is a programmer, nowadays, according to their résumé. It is commonplace for graduate students and post-docs to list one or more of the major programming languages, C, C++, and Fortran 90 under skills, when their knowledge of these languages is hardly better than my restaurant menu German. Worse yet, the situation extends to methods commonly used to solve engineering problems. I've seen plenty of students claim experience with finite element methods, when the most they've done is run a few canned problems they don't understand on commercial software they don't understand.
Finding a good candidate to develop a complex CFD application such as Cats2D is like looking for a needle in a haystack. I've read dozens of résumés from candidates who appear nominally qualified to do this kind of work. In reality none of them could get anywhere at all without intensive training. Their graduate school education is remedial. This situation is harmful to physics-based computing.
Temba, his arms wide
I remember a day in graduate school more than thirty years ago when I came upon an eager puppy wagging his tail in Stan Middleman's lab at UCSD. It was Goodwin. He was fresh out of the Navy and he looked it. Either that or he was auditioning for a ZZ Top cover band. Apparently there was a bit of a competition in the sub fleet to grow these things, and Goodwin excelled at it.
We were from different walks of life, but my seven years spent working in beach area restaurants in a border town had prepared me for almost anything. For Goodwin it was the surfriding public he witnessed daily outside his Ocean Beach apartment that provided the Rosetta stone to my behavior.
Goodwin was the smartest undergraduate I ever met in the chemical engineering program at UCSD, besides myself of course. He was 29 years old, he had passed the Navy's notoriously difficult nuclear propulsion school, and he had served on a fast attack sub. I pity the other students in his class. Just kids! How could they possibly compete. It's a wonder they didn't assassinate him.
On the other hand, he was a teaching assistant's dream. Need a key to grade the homework? Just pull out Goodwin's work, knowing with confidence that it would be free of errors. He makes so few errors, even today, that I must strive to relish each one as I come upon it.
I find it strange that Goodwin and I have never coauthored a research publication. My published works list over sixty different coauthors yet he is not among them. This is unfortunate. Our intellectual and practical collaboration on Cats2D suffuses much of my professional work.
In each paper I've coauthored based on Cats2D simulations, Goodwin did not meet the customary standards for inclusion in the author list. His contributions merited a citation of the code in the reference section. These have piled up over the years, over fifty times now, so anyone who follows my work is likely to notice this relationship. But I think it is not enough.
The methods and algorithms that make Cats2D so special took us years to develop and master. The shared experience of doing it together planted ideas that continue to manifest in my research. I constantly draw on this well of knowledge to practice the art of simulation on complex, nonlinear problems. At any moment I might rely on something Goodwin did years, or even decades, ago that allows me to succeed at a simulation today.
This intellectual synergy deserves recognition, but it takes so long to complete the circuit that Goodwin's contributions end up buried by the passage of time. At the root of the problem is an outdated dissemination model in which we package our research into rigidly formatted articles suitable for the printing press. This totally linear exposition of our research is frightfully limited. It is like streaming data to a serial access tape, which is to say awkward, archaic, and unnecessary.
The entry titled "Turn on, tune in, drop out" further down this page discusses this issue at length. There you can learn about my preferred solution, which is exemplified by this web site. I can publish as much as I want, and I can organize it however I want. This allows me to place Cats2D alongside the research where it belongs, instead of beneath it where Goodwin does not get fair recognition. In a stream of conventional research articles Cats2D fades into the background when in fact it is central to the work every time it is used.
Turn on, tune in, drop out
I've grown disillusioned with the dissemination model of traditional science journals for a few reasons. I enjoy the flexibility and freedom this web site gives me to present my results on a multimedia platform. It allows unlimited use of high quality color images, animated visualizations, slide presentations and so on. Material can be edited at any time to fix errors, clarify points, add new results, and anything else that makes the story better. Best of all, it can be organized and reorganized any way I see fit.
This sort of continuous refinement can't be done in traditional publishing. If you want to add something new, you need to publish something new. Scientists end up churning out a lot of short articles based on a few results that are supplementary to work they've already published. The standard requirements of a journal article demand repetition of general background, methods, literature, etc. Some of this stuff can be off loaded by citing earlier works, but we must always say something in each of these areas for the article to stand alone as a published work. The flip side is that many things get left out of the story. The tools used by many of us, be it a sophisticated lab instrument or a code like Cats2D, have grown too complicated in this day and age to properly document in a journal article. We mostly deal with it by citing references from the literature, but sometimes the relevant information has never been published, and other times it is prohibitive to find and comb through it all.
I acknowledge that science publishers are aware of concerns like these, and now accommodate online supplementary material to articles, including multimedia. But the rigid formatting of the article itself, the process by which it is published, and the loss of copyright to the publisher, all deter me from continuing down that path. Since most of us work in one or a few topic areas for many years, gathering chapter after chapter as our knowledge of a subject grows, why not frame the story as a cohesive book? Surely many a great author has rewritten the first chapter after the last has been finished. Why lock us into each chapter of our story as it first becomes bound by publication? If we ever want to retell that part of the story better, we must write another chapter, sort of the same but sort of different, presumably without violating copyright. It can get awkward.
This dissemination model based on transferring copyright in our scientific works has created an oxymoron, the notion of self-plagiarism. Actual plagiarism is simple to understand: stealing someone else's words and ideas without crediting them for it. But how is it possible to steal our own words? In fact we can't, until we assign copyright to the publisher. We still own the idea but give up the right to publish it again using the same words to describe it. This might seem like no big deal to your typical freelance writer moving from assignment to assignment, but in science we study and write about our pet ideas for decades. If we want to modify one of our articles because we've gained a better perspective on it, it is forbidden to re-publish it because of copyright issues. There are legal ways to collate published materials by written permissions, but most of the time we craft a different article that repeats many of the same things in not quite the same way.
When we do this we are not just skirting copyright issues, we are also skirting the concern that we are duplicating publication of our research in order to gain professional advantage. This concern is taken very seriously. Publishing the same paper in two different journals (or even twice in the same journal!) is a significant ethical violation and has gotten people banned from journals. There is, in fact, a fair bit of self-plagiarism out there, because it is hard to avoid, the way things are done. Much of it is trivial (the methods section you've rewritten so many times), but a pattern of substantial self-plagiarism can raise questions, particularly if it appears calculated to pump your publication count.
So self-plagiarism is this odd umbrella that covers several different issues, none of which has anything to do with actual plagiarism. I think we should simply drop this term and call things by their true name, be it copyright violation against the publisher, professional misconduct against the employer, violation of ethical customs for scientists, or whatever. The act itself, copying our own words, only becomes an issue because there are pathologies in how we do things in science.
Transferring copyright is one of them. I realize the journals allow significant leeway in how authors may continue to share their work after publication, but the restrictions are onerous, nevertheless. Take for example the exclusive right to publish demanded by the journals. Syndicated columnists can publish their work in a hundred newspapers, reaching a vast audience, if they are popular and the papers are willing to pay for it. I'm not suggesting we encourage this in science, I know it's not customary, but there isn't anything unethical about it, either. Frankly, I see it as a business model concern for the science publishers more than anything else.
Likewise, duplicative publishing is not a problem until we strongly tie professional advancement to publishing traditional journal articles, to such an extent that metrics are often employed (basically counting). Everyone knows this encourages all sorts of minor evils, such as gift authorship, the "minimum publishing unit" approach to publishing, frivolous citations to pump impact factors, slice and dice, etc. Writing a "different" paper that isn't too different doesn't bug anyone too much anyway, because it's an easy publication. All these things lead to dilution of intellectual content in the literature, to the detriment of us all.
A useful analogy to writing code can be made here. Software applications of a non-trivial nature either get better or die. If you stop updating a code if will become obsolete as the demands of the computing world change around it. Often we do something called "refactoring", which simply means rewriting a piece of code with the intent to improve it somehow. Think of replacing the failing appliances in your kitchen and installing new cabinets. It is still a kitchen, but it works better, it looks better, and it makes you happier. We should treat our research story this way, as something to continually improve rather than merely accumulating more of it.
The best way to accomplish this is to get off the conventional publishing model and take control of the content ourselves. The internet makes this feasible. The personal research web site is common, but rarely carried out with much ambition. It should become the central expression of one's research, one stop shopping for anyone who follows your work. It should form the primary basis by which your work is evaluated for professional advancement. Cut out the fat and put in the content. Make it a multimedia freak show if you can. Issues with self-plagiarism and manipulation of publishing metrics simply would not exist under this dissemination model. A career based on duplication, repetition, and frequent padding will become much harder to disguise when everything important you've done is organized in one place.
I'm not saying we should stop publishing in the traditional format, but we should reduce how often we do it. Reserve it primarily for mature work that has already been well vetted in its internet ecosystem, and recent work worthy of a breaking news treatment. Periodicals could routinely include a roundup of hot research web sites selected by editors, with commentary added by invited peers. Standards and methods would evolve to enable bibliographic citation of material found at research web sites by persistent URL or DOI. A symbiotic relationship would emerge.
Shaka, when the walls fell
Personal computers became widely available in the 1980s, around the time I started programming. These clunky boxes with their command line interface were mysterious and intimidating to most people. The learning curve was immediate: you couldn't do a thing without memorizing all sorts of obscure commands. Using one was more likely to make someone feel dumb than smart. Even after Apple introduced a more approachable graphical interface, computers were not particularly easy to use.
Some interesting things were done with computers in engineering simulation in the 1980s. Several commercial CFD codes were launched, including Fidap and Fluent. Some researchers, many of them graduate students, succeeded at writing single use codes to solve significant problems. A superficial feeling spread in the community that problem complexity was limited more by available computing power than anything else. People were frequently saying things like "the extension to three dimensions is obvious" without having the slightest idea how difficult it would prove in practice to write, or even conceptualize, a framework for studying 3D problems of arbitrary geometry.
Steve Jobs' drive to bring personal computing to the masses finally succeeded with the introduction of the iMac. By then everyone in the industry had learned much about user behavior that had gone into improving interfaces for the OS and user applications. Hardware was cheap and reliable. Pretty soon Grandma and Uncle Joe were shooting off email and zipping around the internet like pros. Computers were now usable enough that you were more likely to feel smart than dumb using one. It took twenty years to reach this crossover point.
Then something happened that made a lot of sense. Engineering departments stopped teaching the workhorse programming languages. The emphasis shifted to spreadsheets, interpreted languages, toolkits, and simulation applications. This is how engineering is mostly done nowadays. Unfortunately for the small group of people interested in developing physics-based simulation applications, this curricular change de-emphasized the core languages at a time when architectural changes in computers, particularly the introduction of parallelism, was making application development for high performance computing much harder than ever before. The results have been devastating to the progress of physics-based computing.
One of the greatest impediments to reform is a near-universal cultural understanding of computer programming as the quick and easy province of the young. Legends abound of self-taught savants writing brilliant code by their teen years. Most of the time this is a Rubik's cube sort of brilliance, in which a few skills are honed to perfection on some narrow, easily comprehended target. Much of code development at a professional level is unlike this. Read what prolific Quora contributor and software engineer Terry Lambert has to say about computer science education nowadays. The situation is every bit as bad in engineering and other STEM disciplines.
Cogito, ergo sum
Someone at Quora asked "How do you judge an experienced C programmer by only five questions?" Frankly, it's a dumb premise, but I played along and read the responses, many of which offered more than five questions (I was surprised at the number of respondents who casually violated this stipulation without comment). I found myself unable to answer most of these questions. I couldn't even recognize what was being asked in many of them. Apparently I wasn't a C programmer at all, just a clueless hack posing as one.
This didn't seem right to me, especially with all the bragging and boasting about Cats2D that goes on around here. It's fast, efficient, robust, versatile, extensible, and more. It is written in C, and only experienced programmers could have written it. So what is it about my C programming that is so different from the C programmers who wrote these questions?
I quickly recognized that many of these questions related to things that the C language was developed to abstract away from our view. It turns out that many people who gravitated to this question were embedded device programmers. This is a distinctive branch of programming in which a code interacts directly with hardware. All sorts of unusual requirements apply, demanding the most exotic elements of the C language, and a good understanding of the hardware too. These programmers do things and worry about things that have nothing to do with C programming per se.
But I also noticed in these questions some cultural characteristics common to the programming world at large, in that they were often painfully parochial, and not infrequently more concerned with parlor tricks than real world programming. In my world of scientific application programming, if you are using the longjmp command, fiddling with bits, or nesting unions, then you are doing something wrong.
Here are my hypothetical responses to some of the questions I saw:
Q: Can you write two functions in which one executes before main and the other executes after main?
A: No.
Q: Suggest techniques to accelerate IPC between two threads and guess the throughput per second.
A: No.
Q: Swap two variables without using a third variable.
A: Why?

Programming can mean so many different things. It is easy to find good advice on basic programming techniques. It is much harder to find good advice on software architecture or development strategies for large applications. Much of this advice suffers the same parochialism as the questions I talk about above, and does not apply well to scientific application programming.
An example of such advice is given by a popular author who recommends that functions be limited to twenty lines and do only one thing. Abiding by these restrictions would wreck a code like Cats2D. In a scientific application of its size and complexity, functions that are several hundred lines long are often needed to control execution flow among a large number of branches. For example, the function that controls assembly of the residuals in Cats2D is over 700 lines long because of large switch statements over the field equations and their boundary conditions, yet it is very easy to understand, maintain, and extend. This function is the right length for its purpose. Imposing a twenty line limit is arbitrary and inflexible.
Too much other rule-based advice is like this. Someone says that a "clean" code has no loop control statements in it (for, while, etc.) because these should always be handled by library functions (e.g. BLAS) or other constructs. Other people think looping is okay, but believe that nested loops are the devil's handiwork. Imposing rules like these on a code like Cats2D is unworkable.
Unfortunately the best I can come up with on my own are vague and generic guidelines. Make your functions short whenever doing so makes sense, and make them long whenever necessary or desirable. Use loop control constructs if needed, avoid deep nesting if possible, and make exit conditions easy to understand. Organize related data into structures. Handle pointers with care, never put anything big on the stack, and clean up memory when you're done using it. Above all else, don't write spaghetti code.
Nobody finds the sweet spot among these guidelines the first time they write a useful application. Once in awhile someone is lucky enough to start a new code from scratch that anticipates all the failures encountered on the previous attempt. Much of the time, however, the existing code is refactored rather than replaced, allowing major flaws of the original implementation to linger on. One workaround after another wastes time and makes spaghetti code worse.
I don't envision classroom experience doing much to teach programmers how to get it right and avoid spaghetti code when they create an application longer than a few thousand lines. It is so easy to paint yourself into a corner, and you will do it again and again before you learn how to anticipate and avoid it. Accumulating this experience is difficult, especially on your own. In my fourth decade of programming I am still struggling to learn how to write good code. Many a time I wished for a suitable mentor but none was to be had.
I think a lack of mentorship in software development for physics-based computing is a big problem. Application codes in this area are too complicated and computing intensive to approach casually. Mastering good programming technique is essential, but not enough. The step from the classroom to working on a complicated application code is too big for most people to make on their own. Mentorship from an expert application developer could make a world of difference here. A good mentor would have saved me years of grief learning this craft.
But I have never seen any attempt to mentor academic trainees this way. They're barely taught basic programming technique, if that. There seems to be little concern about it, or even recognition that a problem exists. Yet there is significant spending on computing education by the national agencies. Classes are taught, hardware is provided, research is funded, but something is lacking in the coherence and purpose of this spending.
Things have gone on this way so long now that I see no reason to expect change, especially when no one seems to be talking about it. A big part of the problem is that many people working in scientific computing are stuck on the left side of the peak in the Dunning-Kruger curve:

I spent my first ten years climbing this peak, often called "Mount Stupid" for good reason. I spent another fifteen years wallowing in the trough of disillusionment for want of a good mentor. I am clawing my way out of the trough now, and finding a mentor no longer seems so important. It is a protégé I want now, but given the general state of computing education there is no one to be found.*
* I know Goodwin seems like an obvious candidate for this prestigious position, but he is ruled out by the "under 60" age restriction I've placed on it.
Whine and cheese
Let's talk about things that annoy programmers. Three in particular stand out: programming is way harder than it looks, the boss doesn't know how to code, and unclear project specifications are a nightmare. Obviously these are closely related phenomena.
Programming isn't a binary skill, but I sense that many people perceive it that way. A programmer seems like a plumber or a nurse or maybe even a public notary. Either you are one, or you aren't one. At some point knowledge of plumbing saturates and there isn't much in the world of plumbing to learn anymore. Programming ability doesn't saturate this way. It takes years to grasp the basics, and for those who aspire to mastery, the learning never stops. The range of ability, experience, and talent among self-identified programmers is enormous.
Programming is slow, laborious work that demands constant deliberation and care. Bad things happen when it is rushed. Not everything needs to be perfect, but cutting corners in the wrong places will cripple a code. Acquiring the skills to do this well in a large complicated code takes much longer than many people imagine. It is often difficult to successfully extend the capabilities of a large code, and it is always easy to break it trying.
I once knew a professor who boasted his student was going to write a code to solve the Navier-Stokes equations using the finite element method, and do this in two weeks according to a time line they had written down together. An existing linear equation solver would be used, but otherwise the code would be written from scratch in Fortran 77 (this was in the early 1990s).
The absurdity of this cannot be overstated. Even Goodwin could not do this in fewer than three months, and he's a freak. Six months would be fast for a smart, hard working graduate student to do it. Being asked to accomplish something in two weeks when it really takes six months is confusing and demoralizing.
Unfortunately the situation hasn't gotten any better in the intervening quarter century.